Основные понятия мониторинга #
Система мониторинга - набор инструментов, позволяющий снимать метрики со всех узлов инфраструктуры и сохранять их в единой базе для последующего анализа.
Метрика - любой показатель, который тем или иным образом харектеризует систему, например показатель LA, количество использованной памяти и п.т.
Узел инфраструктуры - любой используемый компонент, будь то сервер, ВМ или сетевое устройство.
Push model - агент отправляет метрики на центральный сервер системы мониторинга.
Pull model - центральный сервер самостоятельно опрашивает агентов.
Рассмотрение pull или push модели идет со стороны системы мониторинга.
Уровни мониторинга #
- Системный - сбор метрик ОС и железа
- Сервисный - то же самое для всех используемых сторонних сервисов, например БД, веб-серверов, систем оркестрации и т.д.
- Приложения - мониторинг самописных приложений
Задачи, решаемые системой мониторинга #
- Оповещение о возникновении проблем.
- Анализ инфраструктуры; прогнозирование потребности к масштабированию.
- Предоставление исторических данных для расследования инцидентов.
- Констроль оптимизации приложений.
Ключевые особенности Prometheus #
- Встроенная TSDB.
- Multi-dimentional data model - в БД хранятся не только имена метрик, но и теги, привязанные к ним. Это позволяет создавать более гибкие выборки, что помогает при анализе.
- PromQL - язык запросов ко встроенной TSDB.
- Используется pull модель сбора метрик; сервер опрашивает агентов по HTTP с использованием собственного plain-text протокола.
- Множество вариантов Service Discovery, что упрощает интеграцию с различными платформами.
Архитектура #
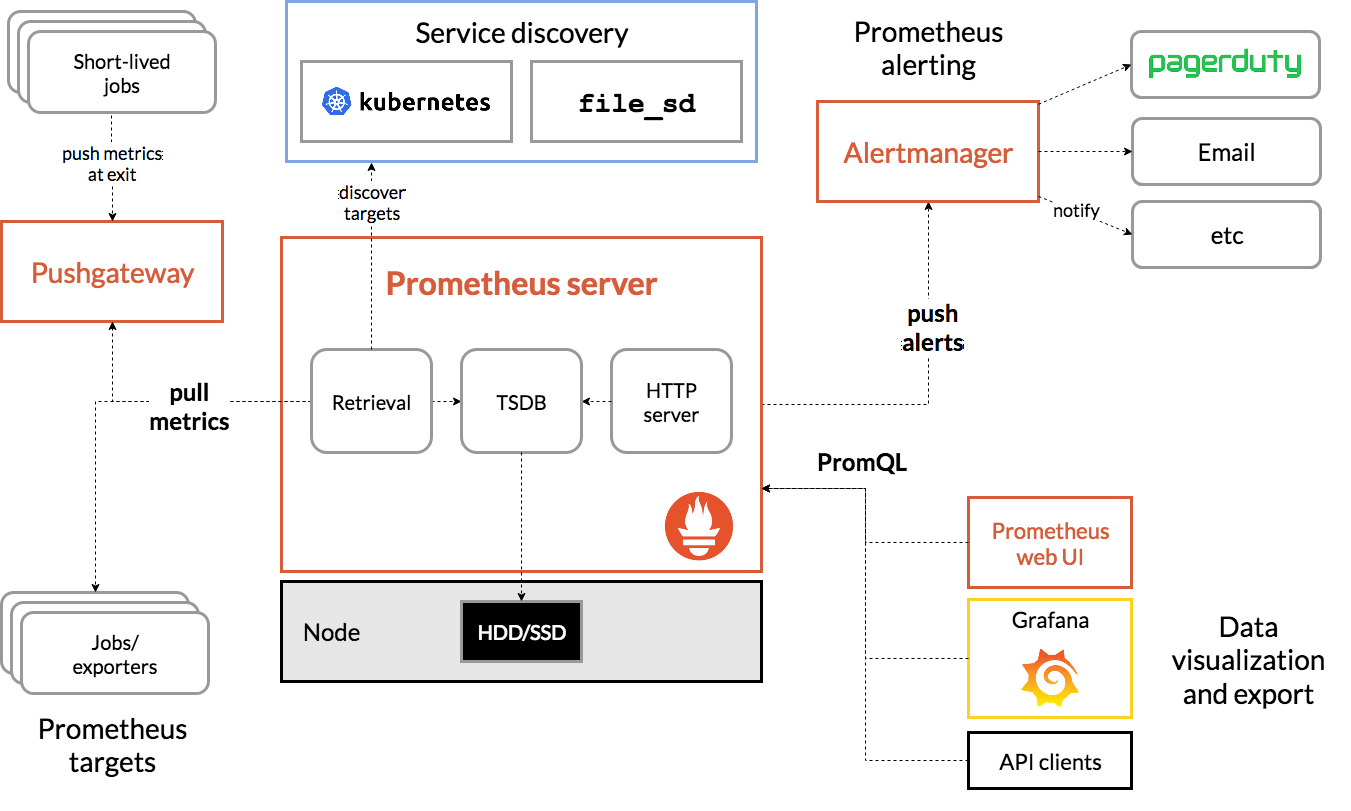
Описание архитектуры в документации.
Основные компоненты:
- Prometheus сервер, содержащий:
- TSDB для хранения метрик
- HTTP-сервер для работы web UI
- модуль retrival, отвечающий за опрос агентов и получение от них метрик
- модуль service discovery, определяющий цели для опроса метрик
- модуль алертинга, отправляющий сообщения о проблемах в Alertmanager
- Exporters - агенты, устанавливаемые на узлах инфраструктуры, которые отдают метрики
- Alertmanager - отдельный сервис, принимающий от Prometheus-сервера оповещения о проблемах и отправляющий их в соответствующие каналы (email, slack, telegram)
- Дополнительные сервисы, такие как Grafana, которые могут подключаться к Prometheus и забирать из него данные для последующей обработки
Установка Prometheus #
Docker #
docker run -p 9090:9090 -v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
Ручная #
- Скачиваем архив с официального сайта
- Распаковываем содержимое и размещаем его по требуемым директориям
- Создаём systemd unit и запускаем сервис
Пример unit-файла для Prometheus-сервера
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
ExecStart=/opt/prometheus/prometheus \
--config.file=/path/to/prometheus.yml \
--storage.tsdb.path=/path/to/data \
--web.console.templates=/path/to/consoles \
--web.console.libraries=/path/to/console_libraries
[Install]
WantedBy=default.target
Основные файлы и директории архива:
- console_libraries/ - содержит библиотеки для HTML-шаблонов
- consoles/ - содержит шаблоны HTML-страниц для web UI
- prometheus - исполняемый файл сервера
- prometheus.yml - его конфиг
- promtool - утилита для проверки конфигурации, работы с TSDB и получения метрик
Основные параметры запуска Prometheus-сервера:
- –config.file=“prometheus.yml” - путь до конфига
- –web.listen-address=“0.0.0.0:9090” - адрес, которые булеи слушать сервер
- –web.enable-admin-api - включить или отключить административный API через веб-интерфейс
- –web.console.templates=“consoles” - путь к директории с шаблонами html
- –web.console.libraries=“console_libraries” - путь к директории с библиотеками для шаблонов
- –web.page-title - заголовок веб-страницы (title)
- –web.cors.origin=".*" - настройки CORS для веб-интерфейса
- –storage.tsdb.path=“data/” - путь для хранения time series database
- –storage.tsdb.retention.time - время хранения метрик по умолчанию 15 дней, все, что старше, будет удаляться
- –storage.tsdb.retention.size - размер TSDB, после которого Prometheus начнет удалять самые старые данные
- –query.max-concurrency - максимальное одновременное число запросов к Prometheus через PromQL
- –query.timeout=2m - максимальное время выполнения одного запроса
- –enable-feature - флаг для включения различных функций, описанных здесь
- –log.level - уровень логирования
Экспортеры #
Принцип работы:
- прослушивает указанный в конфигурации порт на предмет входящих подключений
- при поступлении запроса, опрашивает систему, которую он мониторит (например ОС в целом или конкретный сервис)
- Prometheus обращается к экспортеру по заданному адресу с указанной периодичностью и получает в ответ все собранные метрики в текстовом формате
- Prometheus сохраняет полученные данные в локальную TSDB
Обычно экспортеры отдают метрики на http://exporter.url/metrics
Для сбора системных метрик в UNIX-like системах используется node_exporter. Собираемые им метрики группируются и собираются отдельными коллекторами, что позволяет гибко настраивать собираемые данные. К примеру, при запуске экспортера можно отключить сбор метрик ФС или CPU, если возникнет такая необходимость.
Официальная документация не рекомендует запускать node_exporter в Docker-контейнере, так как для его нормальнйо работы потребуется примонтировать все существующие ФС. Кроме того, ему нужен доступ к host-системе для сбора всех метрик.
Пример unit-файла для _node\_exporter_
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
ExecStart=/path/to/node_exporter
[Install]
WantedBy=multi-user.target
Формат метрик #
metric_name{tag1="key1", tag2="key2"} X
metric_name - имя метрики, используемое в запросах к Prometheus.
В фигурных скобках указына теги для данной метрики.
X - здесь: текущее значение указанной метрики
Подключение экспортера #
Добавить новую цель для сбора метрик Prometheus’ом можно через его конфиг. Ниже пример статической конфигурации:
global:
# there are global parameters of a Prometheus server in this section
scrape_interval: 15s
scrape_configs:
# there are scrape targets described in this section
# node_exporter target example
- job_name: 'node'
# redefine scrape_interval for a particular job
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
PromQL запросы #
Проверить корректность подключения Prometheus-сервера к экспортерам можно при помощи promtool:
promtool query instant http://localhost:9090 up
# up{instance="localhost:9100", job="node"} => 1 @[1617970210.143]
При помощи promtool можно выполнять произвольные запросы к встроенной TSBD, например:
promtool query instant http://localhost:9090 'node_disk_written_bytes_total'
# node_disk_written_bytes_total{device="vda", instance="localhost:9100", job="node"} => 52323148800 @[1617970275.39]
Помимо тегов, отдаваемых непосредственно экспортером, Prometheus перед записью метрик в TSDB также добавляет собственные:
- instance - адрес экспортера, с которого получена метрика
- job - имя задания из, указанное в конфиге сервера
При необходимости можно добавить кастомные теги для каждой цели:
- job_name: 'node'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
labels:
env: 'dev'
Теперь метрики с этого из этой группы экспортеров будут содержать кастомный тег:
promtool query instant http://localhost:9090 'node_disk_written_bytes_total'
# node_disk_written_bytes_total{device="vda", env="dev", instance="localhost:9100", job="node"} => 52338947072 @[1617970356.777]
Получить данные за определенный промежуток времени можно указав его в квадратных скобках после запроса:
promtool query instant http://localhost:9090 'node_disk_written_bytes_total{env="dev"}[1m]'
Мониторинг приложений #
Существует множество как официальных, так и поддерживаемых сторонними разработчиками клиентских библиотек для имплементации Prometheus экспортеров. Это позволяет относительно просто добавить возможность собирать метрики непосредственно из приложения.
mkdir -p app/src/app
cd app/src/app
package main
import (
"net/http"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
http.Handle("/metrics", promhttp.Handler())
http.ListenAndServe(":2112", nil)
}
export GOPATH=/path/to/app
go mod init
go get
go build main.go
./main
curl localhost:2112
python3 -m venv .venv
source .venv/bin/activate
pip install prometheus-client
from prometheus_client import start_http_server, Summary
import random
import time
# Create a metric to track time spent and requests made.
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
# Decorate function with metric.
@REQUEST_TIME.time()
def process_request(t):
"""A dummy function that takes some time."""
time.sleep(t)
if __name__ == '__main__':
# Start up the server to expose the metrics.
start_http_server(8000)
# Generate some requests.
while True:
process_request(random.random())
python app.py
curl localhost:8000
Дополнительные материалы:
Приём метрик по push модели #
Несмотря на то, что по умолчанию Prometheus работает по pull модели, вместе с ним можно воспользоваться и push моделью. Для её реализации существует специальный экспортер - pushgateway.
Push-архитектура может быть применена, в случае, когда нам нужно собрать метрики с короткоживущего объекта. Таким объектом может быть, например, задание cron или, скажем, ETL-процесс, для которого важны итоговые метрики.
Официальное описание случаев, для которых следует применять pushgateway.
Установка и запуск #
Установка в целом такая же, как и у других компонентов.
Страница, где можно скачать релиз для ручной установки.
В качестве (предпочтительной) альтернативы можно воспользоваться Docker:
docker run -d -p 9091:9091 prom/pushgateway
Основные параметры запуска _pushgateway_:
- –web.config.file="" - Экспериментальная опция, позволяющая указать путь к конфигурации для включения TLS при обработке запросов.
- –web.listen-address=":9091" - адрес, на котором pushgateway будет ожидать входящих подключений.
- –web.telemetry-path="/metrics" - путь, по которому будут доступны метрики для Prometheus.
- –web.enable-lifecycle - разрешает выключать pushgateway через запрос API.
- –web.enable-admin-api - включает административный API, с помощью которого на данный момент можно только удалить все метрики.
- –persistence.file="" - файл, в котором pushgateway будет сохранять полученные метрики. По умолчанию они хранятся в памяти и теряются при рестарте.
- –persistence.interval=5m - как часто следует сохранять метрики в файл.
Отправка метрик в pushgateway #
По умолчанию pushgateway слушает на порту 9091 и имеет собственный web UI.
Алгоритм работы:
- метрика отправляется в pushgateway через HTTP API
- pushgateway добавляется в качестве одной из целей Prometheus-сервера
- Prometheus-сервер забирает метрики из pushgateway при обращении к стандартному эндпоинту
/metrics.
echo "cron_app_processed_users 112" | curl --data-binary @- http://localhost:9091/metrics/job/cron_app
echo "cron_app_payed_sum 13423" | curl --data-binary @- http://localhost:9091/metrics/job/cron_app
Флаг --data-binary отправляет полученные данные POST-ззапросом как есть, никак их не изменяя.
Стоит отметить сообенность формирования URL: job - это лейбл, а cron_app - его значение. По этому тегу pushgateway будет группировать метрики.
При запросе метрики будут выглядеть так:
curl http://localhost:9091/metrics
# TYPE cron_app_payed_sum untyped
cron_app_payed_sum{instance="",job="cron_app"} 13423
# TYPE cron_app_processed_users untyped
cron_app_processed_users{instance="",job="cron_app"} 112
... skipped ...
# HELP push_failure_time_seconds Last Unix time when changing this group in the Pushgateway failed.
# TYPE push_failure_time_seconds gauge
push_failure_time_seconds{instance="",job="cron_app"} 0
# HELP push_time_seconds Last Unix time when changing this group in the Pushgateway succeeded.
# TYPE push_time_seconds gauge
push_time_seconds{instance="",job="cron_app"} 1.6208582543334155e+09
... skipped ...
Последние две метрики:
- push_failure_time_seconds - время, когда последний раз провалилась запись в эту группу
- push_time_seconds - время последней успешной записи
Их можно использовать для отслеживания самого факта отправки метрик.