Scalability and elasticity #
Scalability - the ability of a system to increase resources to accommodate increased demand. This can be done vartically or horizontally, and is not necessarily automated.
Elasticity - the ability if a system to increase and decrease resources allocated (usually horizontally) to match demand, and implies automation.
AWS autoscaling resources:
- Auto Scaling groups
- spot fleet
- ECS
- DynamoDB
- Aurora Read Replicas
Scaling strategies:
- availability
- balanced
- cost
Launch template:
- operational excellence:
- versioning for rollback, re-use or even default templates
- use for regular EC2 launch tasks
- cost optimization:
- utilize T* unlimited instances, dedicated hosts
- on-demand and spot at the same time
- reliability, performance efficiency:
- multiple instance types
Autoscaling operations:
- autoscaling policies
- monitoring ASG limits
- deploy launch templates
- lifecycle hooks
- cooldown periods
- warm pool configuration
Autoscaling scenarios:
- stateless web apps
- unpredictable traffic
- steady-state groups
- message consumer apps
Autoscaling anti-scenarios:
- monolithic applications (singleton instance)
- applications with fixed IP address
- applications with many manual deploy steps
- applications with short, large, random traffic spikes
Caching solutions #
CloudFront #
CloudFront basics:
- global scope
- namaged CDN
- SSL termination
- cache reads and writes
CloudFront operations:
- HTTP redirect to HTTPS
- edge location selection
- ACM (Amazon certification manager) cert integration
- IAM cert integration
- multiple origins
ElasticCashe #
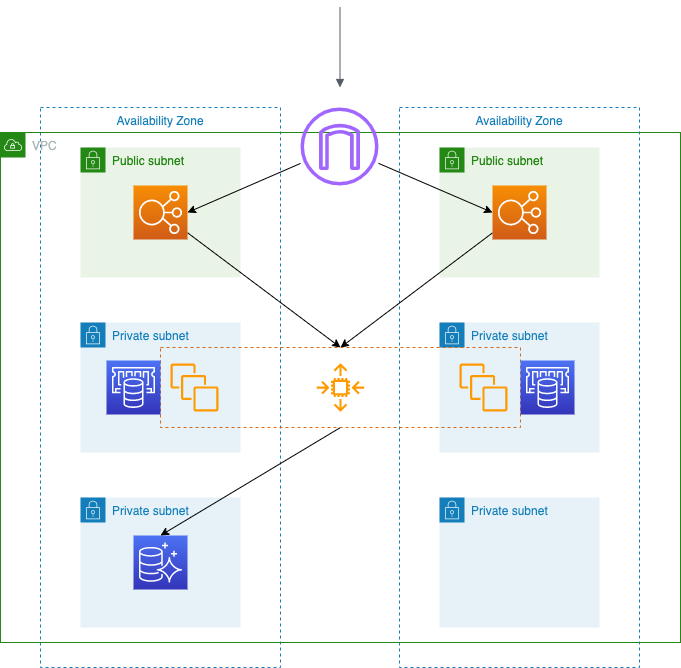
Elasticcache can help absorb traffic spikes, reduce latence, especially for same-AZ traffic.
We can use Memcached or Redis.
Elasticache basics
- Memcached:
- AZ scoped
- managed in-memory
- volatile
- all endpoints writable
- Redis:
- AZ scoped
- managed in-memory
- persistent (it replicate the same cache for each node in the cluster)
- 1 write endpoint
- sharding option
RDS and aurora replicas #
RDS resilience #
RDS may has read replicas in each AZ (but in one region), that can be promoded to primary.
Also possible to use cross-region read replicas (except SQL server).
Multi-AZ deployment as a configuration option allows you to deploy one or more standby node, which can be promote to primary in case of some issues with primary node.
Satndby node will promote to the primary in next cases:
- resize instance
- OS Patching
- initiate reboot with failover
- AZ-scoped availability issue
RDS read replicas #
- unique endpoint
- separate implementation, than Multi-AZ
- up to 5 RRs per primary
Aurora failover conditions #
Failover with existing replicas flips DNS CNAME, promotes replica - takes ~30s.
If multiple replicas are present, customer can set replicas priority and Promotion tiers.
Failover with Aurora Serverless launches replacement in new AZ.
If no replicas and not running Serverless, Aurora attempts new DB instance in same AZ as primary on best-effort basis.
Aurora read replicas:
- single endpoint
- replace multi-AZ
- up to 15 RRs per primary
- +5 RDS RRs per primary
- promotion tier support
Loosely Coupled Architectures #
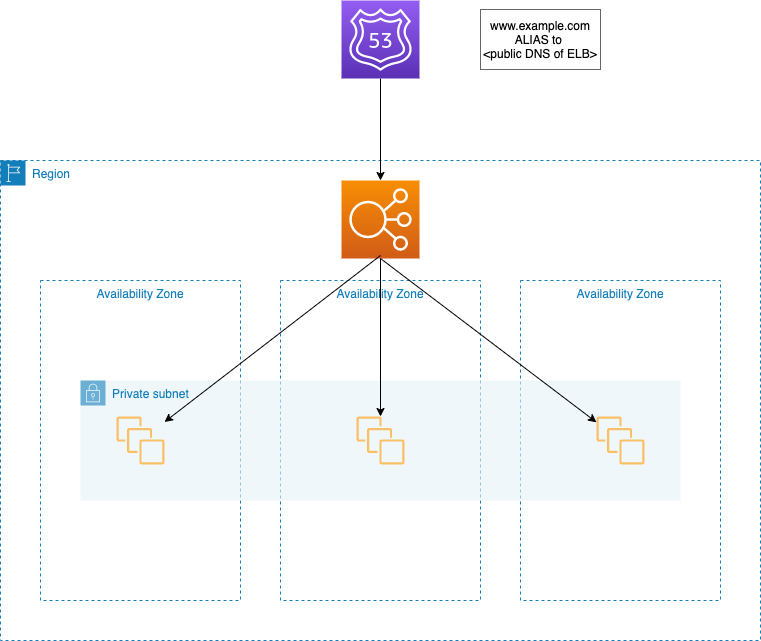
Route 53 may do the helth checks for multiple ELBs in defferent regions. And in case of failure of primary ELB it will switch DNS ALIAS to secondary ELB automatically.
In addition to helth checks Route 53 may use Latence-based routing. And if all ELBs are unavailable it may return static site from S3 as response.
S3 + Lambda integration. We can trigger Lambda function by uploading a file to the S3.
HA and resilience #
ELB and Route 53 Health Checks #
Route 53 Health cheks basics:
- monitor an endpoint
- endpoint
- IP address
- host name
- domain name
- protocol
- HTTP/HTTPS
- path (optional)
- TCP
- HTTP/HTTPS
- port (single or range)
- endpoint
- monitor other health cheks (calculated)
- up to 256 other HCs
- monitor CW alarms
- only one CW alarm may be monitored
Load balancers:
- Classic
- Network
- Application
- Gateway
ELB HC basics:
- check an EC2 instance
- supported by all 4 types of LBs
- check an IP address
- supported by all LBs, except Classic
- check a Lambda function
- supported only by Application LB
LB protocol support
| TCP Ping | HTTP | HTTPS | |
|---|---|---|---|
| CLB | + | + | + |
| NLB | + | ||
| ALB | + | + | |
| GWLB | + | + | + |
Single AZ and Multiple AZ Architectures #
EC2 Auto scaling:
- deploy into a single AZ for:
- performance
- colocation with other resources
- deploy into multiple AZ for:
- resilience
- cost optimization
ELB:
- deploy into a single AZ for:
- performance
- colocation with other resources
- deploy into multiple AZ for:
- resilience
FSx filesystem:
Only supports one AZ for data. But it creates an ENI in a single A which can be reached from multiple AZs.
RDS:
- deploy into a single AZ for:
- cost optimization
- deploy using Multi-AZ:
- resilience
- synchronous replication
- deploy Read Replicas for:
- further resilience
- horizontally scaled reads
Fault-tolerant Workloads #
EIP (elastic IP address):
- region scoped
- can be ressigned
- it is static
EFS:
- resion scoped
- durable
- data is replicated around the region
- you can acces to the FS directly with mount targets:
- AZ-scoped
- can be accessed cross-AZ
- can specify directory and userID
- can be mounted to:
- EC2
- ECS
- EKS
- lambda function
Route 53 Routing #
Routing options
- simple routing
- traditional DNS - each resord has the same weight
- weighted routing
- you can assing weight from 0-255 for each endpoint
- in case of weight 0, this endpoint won’t be returned
- latency-based routing
- DNS response determined by lowest latence from client
- failover routing
- you have primary and secondary endpoints
- secondary will returned only if primary fails health cheks
- also you can have multiple primary endpoints
- requires health checks
Alias records - are pointers to some AWS resources:
- CloudFront Distributions
- Elastic Beanstalk Environment
- ELB
- S3 static site endpoints
- route 53 record in the same zone
- VPC endpoint
- API gateway
- Global accelerator
Backup and restore #
Automated Snapshots and Backups #
Authomated backups
| Service | Enabled by default | Can be disabled | Retention(days) | PITR* |
|---|---|---|---|---|
| EC2 | + | 0-∞ | ||
| RDS | + | + | 0-35 | + |
| Aurora | + | 1-35 | + | |
| Redshift | + | 1-35 | ||
| DynamoDB | + | 35 | + |
* Point in time recovery
EC2 has no native backup feature, you can use AWS Backup or DLM(Data Lifecycle Manager) for this task.
Manual backups
| Service | AWS backup | Rotate | Retention(days) | Copy or share |
|---|---|---|---|---|
| EC2 | + | ∞ | + | |
| RDS | + | ∞ | + | |
| Aurora | + | ∞ | + | |
| Redshift | ∞ | + | ||
| DynamoDB | + | ∞ |
You may implement rotation by your own or use AWS Backup to gain that ability.
EC2 data lifecycle manager (DLM) allows you to create:
- EBS snapshots
- EC2 AMIs
- Cross-account copy
- Snapshot/AMI rotation
- No unique features against AWS Backup
AWS Backup resources
- backup vault
- backup plan
- backup job
- restore point
AWS Backup workflow
- Resources assignments for Backup plans require tags to function. So you have to create a tag
backup:true - Backup vaults hold restore points and provide resource-level access control
- Backup plan provide the integration between resources, jobs abd vaults
- Each backup job generates a single restore point in a vault
- Vaults can hold multiple restore points from different resource types
Backup plan - is a siries of a tasks that you have to compleate. You need to determine:
- backup rules
- ways to creation:
- template
- interactive build
- JSON
- anatomy
- backup vault
- frequency
- time period
- cron expression
- retention
- copy (optional)
- remote region
- rmeote account
- ways to creation:
- resource assignments
- specify tags
Database Restore Tasks #
RDS restore task
# Automated backup
# *
aws rds restore-db-instance-to-point-in-time
# Manual snapshot
# *
aws rds restore-db-instance-from-db-snapshot
# Backup in S3
# *
aws rds restore-db-instance-from-s3
# Promote read replica
aws rds promote-read-replica
* - these commands create a new DB instance (and potentially new endpoint) during restore
Aurora restore tasks
# Continues backup
# *
aws rds restore-db-instance-to-point-in-time
# Manual snapshot
# *
aws rds restore-db-instance-from-db-snapshot
# Backup in S3
# *
aws rds restore-db-instance-from-s3
# Promote read replica
aws rds promote-read-replica
# Backtrack
aws rds backtrack-db-cluster
* - these commands create a new DB instance (and potentially new endpoint) during restore
BynamoDB
# On-demand backup
aws dynamodb restore-table-from-backup
# PITR
aws dynamodb restore-table-to-point-in-time
Both of these create a new table during restore
Redshift
# all snapshots
# *
aws redshift restore-from-cluster-snapshot
# restore table
aws redshift restore-table-from-cluster-snapshot
# relocate a cluster to another AZ in the same region
aws redshift modify-cluster --availability-zone
* this creates a new cluster endpoint during restore
S3 Versioning and Lifecycle Rules #
By default S3 versioning is disabled. When you enable versioning:
- version ID attached to each version of an object
- delete operation attaches a delete marker to the object (and doesn’t actually delete the data)
Versioning is a good way to avoid accidental deletion.
Considerations:
- cost of many versions
- performance of many versions
- more complex lifecycle rules
Lifecycle rules - options
- transition current version
- transition previous version
- expire current version
- delete expired delete markers
- delete incomplete multipart uploads
Lifecycle rules considirations:
- object size
- object age requirements
- bucket or prefix scope
- tag scope
- conflicting rules
Glacier vault lock
- permission policy
- use to deny deletes
- enforce lifecycle
- locked after 24 hours
S3 replication options:
- same-region, same account
- cross-region, same account
- cross-region, cross-account (ownership can be changed to that of the destination bucket)
- multiple bucket destination
- storage class of a destination can be changed for cost optimisation
- rules are evaluated in priority order
- multy-way replication between 2+ buckets
- pre-existing objects can only be replicated by AWS support
All replication requires:
- versioning enabled at source and destination
- and IAM Role for permissions